
For a better user experience, almost every website feeds its data through Ajax. One indication is when the displayed data changed without page transition. Thus, how to scrape the Ajax website is one of the must-have tools on our toolbelt. Fortunately, Python has a bunch of libraries to handle such web scraping scenarios. That makes scraping Ajax’s website using Python as easy as cake.
Web scraping alone is usually only one of the challenges. Often, another challenge arises when performing Ajax web scraping. The following story will elaborate on another exciting challenge when scraping the exhibitor list from the ASD Market Week website.
Web Scraping
One fateful morning, as the first rays of light danced on your eyelids, you stirred with a start, realizing that the familiar, annoying ring of your alarm hadn’t disturbed your slumber.
You bolted upright, your heart pounding as you glanced at the clock. It was much later than you had ever slept on a workday. You realized you had precious little time to prepare for the day ahead. The morning ritual of brewing coffee, toasting bread, and savoring a leisurely breakfast was a luxury you could ill afford today.
With haste, you threw on clothes and dashed out of your apartment. The streets were already buzzing with activity, a symphony of car horns and hurried footsteps that seemed to mirror your sense of urgency.
As you arrived at the office, you felt that everyone who was used to seeing you come like clockwork gave you a curious glance. You mumbled hurried apologies as you squeezed past them, aware you disrupted the morning’s usual flow.
With a cheerful grin and a twinkle in his eye, Mr. Jennings, a peculiar character everyone fondly referred to as “The Funny Boss,” greeted with his usual enthusiasm, “Good morning, Jhon! Or is it ‘almost afternoon’? How’s the day treating you?”
With your half-hearted smile, “Oh, you know, Mr. Jennings, the usual hustle and bustle of the office.”
Mr. Jennings leaned in, his face suddenly taking on a conspiratorial tone. “Well, Jhon, I’ve got something that might make your ‘usual’ day a bit more interesting.” He paused for dramatic effect, his eyes dancing with mischief.
Intrigued, you raised an eyebrow. “What’s that, Mr. Jennings?”
“We need to scrape exhibitor data from the internet for an upcoming event. But we’re going to do it in a fun and, dare I say, hilarious way.”
“How are we going to do this, Sir?”
Mr. Jennings leaned in closer, his voice dripping with mischief. “We’re going to turn this into a game, Jhon. A game of ‘Scrape the Exhibitor.’ Here’s how it works: I’ve hidden clues around the office. Each clue leads to a webpage with exhibitor data. You follow the clues, find the data, and scrape it. Simple, right?”
You couldn’t help but chuckle at the clever twist on the task. “Sounds like fun, Boss. Where’s the first clue?”
With a theatrical flourish, The Funny Boss handed a sealed envelope. “Here’s your first clue: ‘Where the paper piles high, and the coffee’s always nigh, find the first exhibitor in the sky.'”
You laughed and set off on your digital scavenger hunt. The first clue led to the office printer, where a piece of paper was waiting with a URL. You entered the URL, and sure enough, it contained the exhibitor data.
Scrape Exhibitor List
ASD Market Week is the URL on the paper.
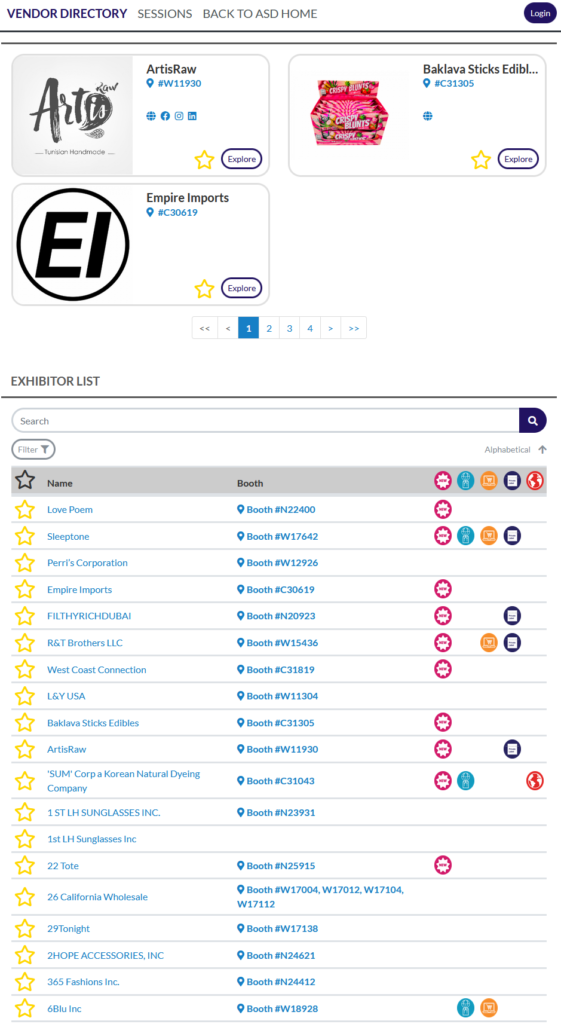
It’s a B2B wholesale trade show held in Las Vegas. This trade show is the largest in the United States for consumer merchandise, featuring over 1,800 vendors and a diverse array of up-to-date products. It occurs bi-annually and welcomes retailers and distributors of all scales.
It looks like Mr. Jennings wants to find new suppliers for the company’s merch portfolio.
Clicking one link, you find other data such as an address, keywords, and the exhibitor products.
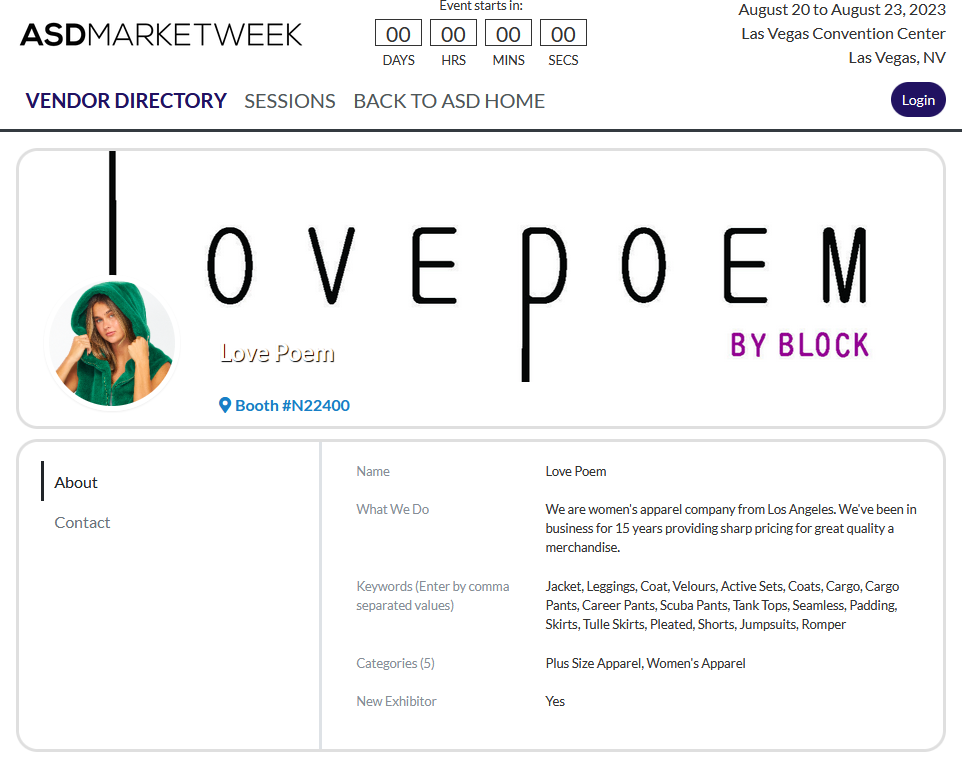
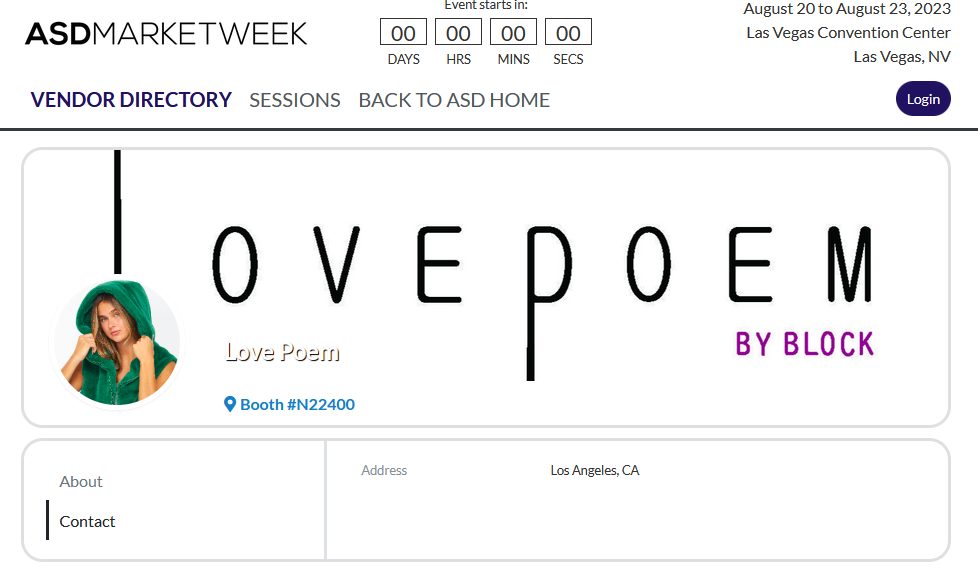
“So, I need first to scrape the exhibitor list from the list page and then scrape each exhibitor’s page.” You whispered.
Network Tab on Developer Tools for Inspecting Network’s Traffic
Next, you open your browser’s Network Tab, click the list’s next page, and find exciting data.
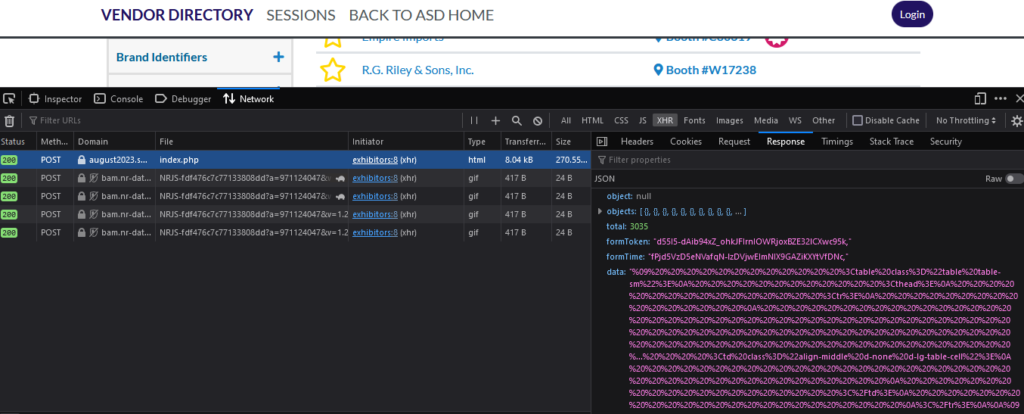
To open the Browser’s Developer Tools you can press “Command + Option + I” (Mac) or “Ctrl + Shift + I” (Windows).
It seems the data dynamically changed using Ajax. The data being transported using Ajax will make the process easier. But let’s make sure by viewing the page source and finding one exhibitor’s name.
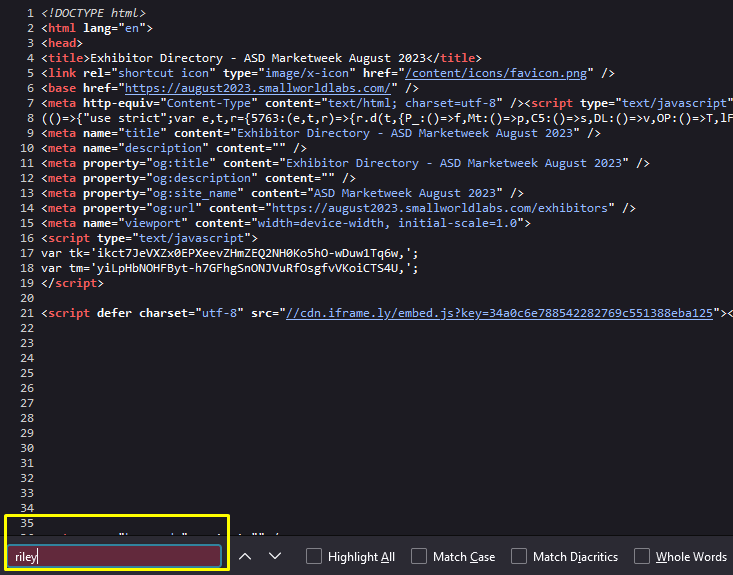
Yep! The exhibitor names aren’t shown on the page source, confirming Ajax is the data provider.
How to view page source in a browser: “Command + Option + U” (Mac) or “Ctrl + U” (Windows).
The next step, from your experience, is to write a simple web scraping script to gain an understanding of how the server treats a web scraping action. Often, the site served you well for any requests from the real browser. But it’s a different story if the scraper initiates the requests.
At this point, you realize the hunger began to slip from your thoughts. The engaging challenge commanded your full attention, gradually causing your appetite to fade into the background.
Edit and Resend Network Request
Before writing any code, first, you need to see the Network Tab to get four elements:
- The URL
- HTTP request methods (GET or POST)
- Request (if POST method used)
- Request Headers
Recognizing those elements is essential because the script must mimic the browser’s request to the server using the same parameters to get the same responses as in the browser.
In this case, the URL you’ll use is https://august2023.smallworldlabs.com/index.php.
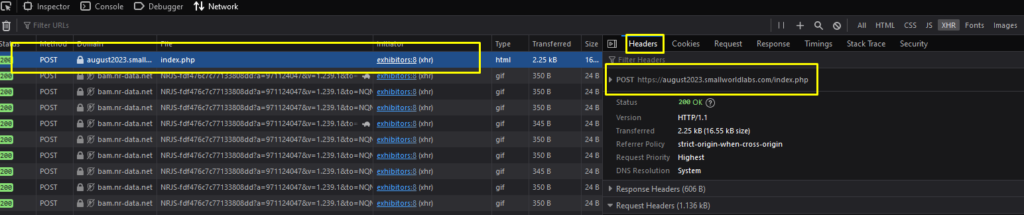
When the POST method is used for the request, it means some data must be sent. You can open the Request Tab to see what data is needed.
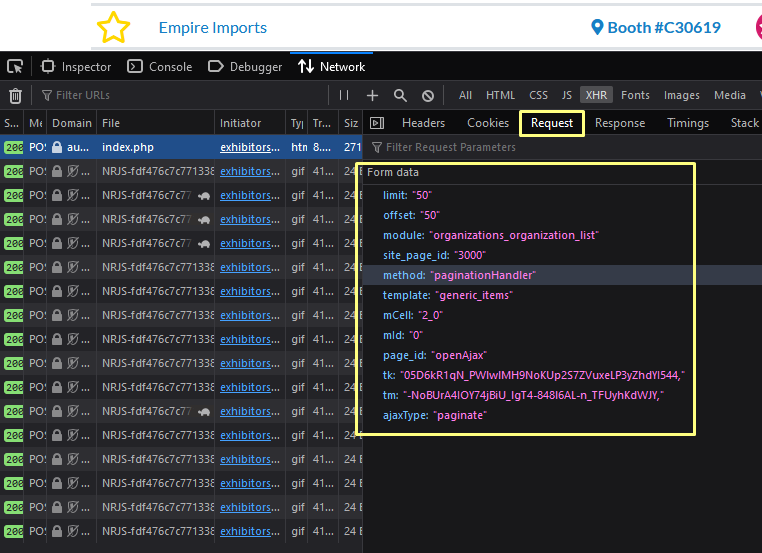
The last element you need to grab are the Request Headers.
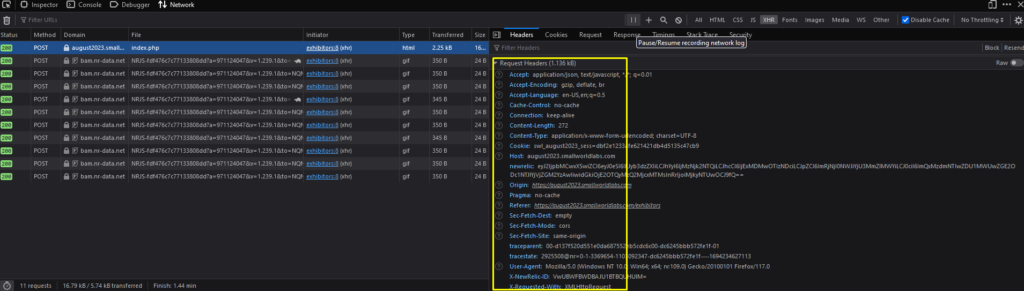
You found it overwhelming to type all parameters from the Request Headers and POST Request. Sure, you can always right-click the URL and copy the Request Headers, but it’s still a large amount of work, you think.
But there is one trick you’ll find helpful.
Use the Edit and Resend feature offered by Firefox and Edge.
To achieve this, Right-click on the URL, click Edit and Resend.
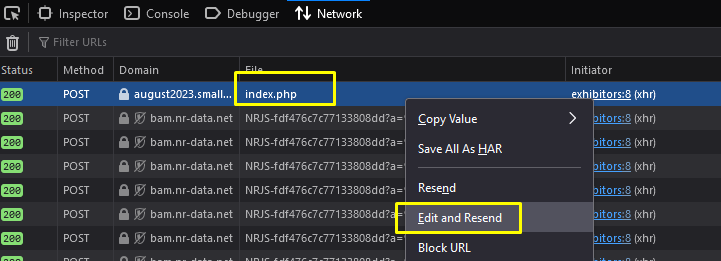
The browser will open a new window containing Request Headers and Body sections. You can play a little on those sections, such as unchecking some headers or modifying parameters on the Body.
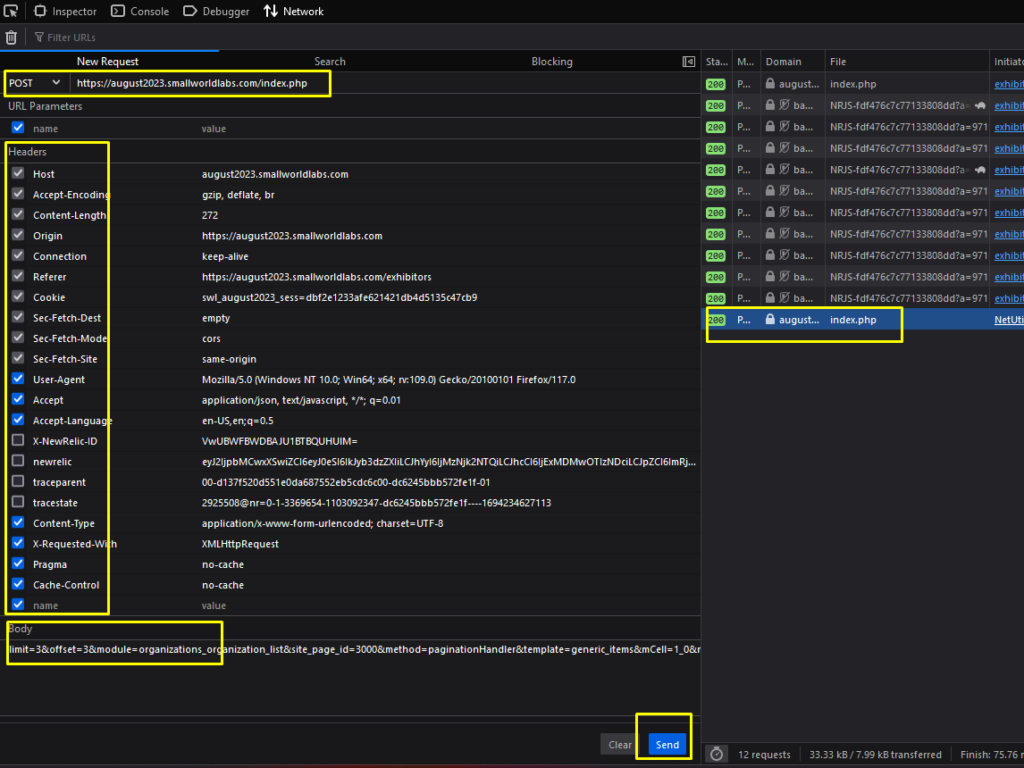
If you hit Send and get the proper result in the Response Tab, Congratulations! You’ve succeeded in minimizing the code-writing time and reducing the bandwidth used.
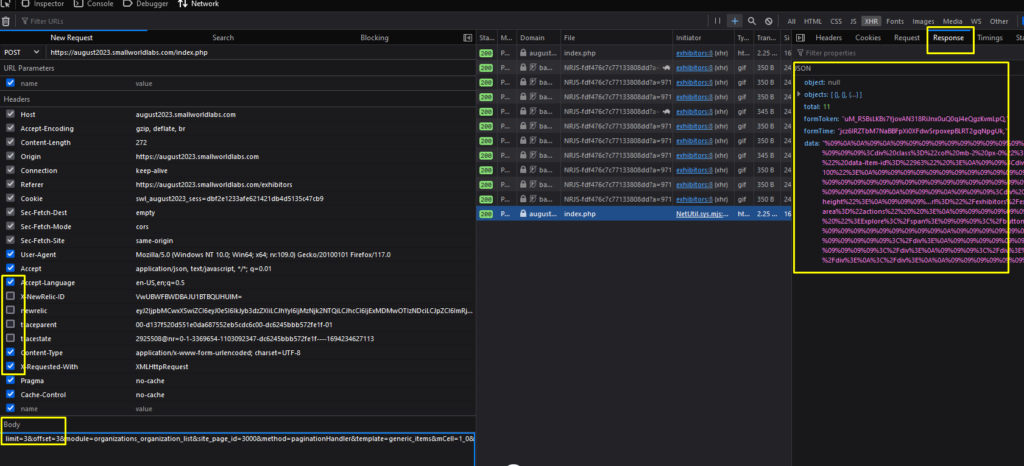
This step lets you avoid the hashed value parameters in the Request Headers and Post’s body. Often, the server uses parameters to monitor its activity, performance, etc., which doesn’t directly affect the served data to the users. On the other hand, finding those parameters is time-consuming and adds complexity to your script; thus, it’s always a good call if you can skip them.
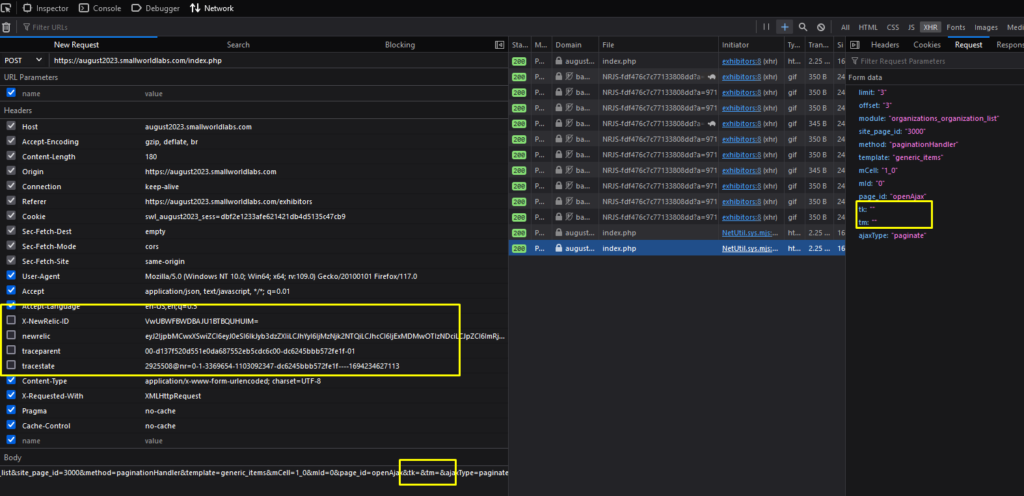
If you are a Chrome user, there are workaround to get the same result. Right-click on the URL, choose Copy as cURL, and treat it as a cURL on your terminal.
Web Scraping with Python
Now, you can write and test a Python script to scrape the Ajax data from all pages. First, you’ll need to scrape all exhibitor URLs and then scrape each link.
When scraping the web, it’s always wiser to divide tasks into small parts and do them individually. After finishing the small part, save the result, i.e., to an HTML/JSON/CSV/MS Excel format. So, if the scraping stops, you don’t need to redo the whole process.
You decide to split the web scraping task into three separate phases. The first phase is to get the exhibitor list; the second is to download each exhibitor’s page as HTML, and the last is to parse the HTML and save it as MS Excel.
Let’s dive in.
Scraping Ajax using Python
For the first phase, you’ll get data similar to this. Basically, the script will pull the exhibitor’s name and individual link to process in the next phase.
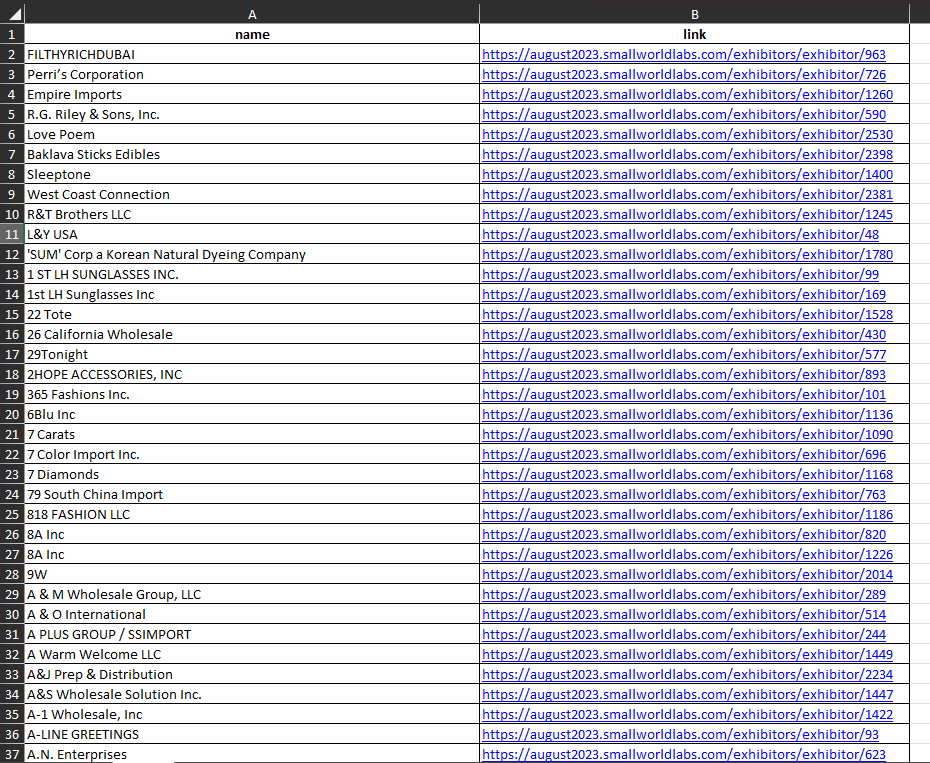
Let’s discuss the Python web scraping script chunk by chunk.
For the final code, please refer to this section.
import requests, math
import pandas as pd
from bs4 import BeautifulSoup
from urllib.parse import unquote
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)This part contains the required libraries for the process. Fortunately, you can use Python requests for the scraping task. It’s a lightweight library and relatively fast; ergo, it works excellently in a limited environment.
page_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.5',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:102.0) Gecko/20100101 Firefox/102.0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1'
}
json_headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.5',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'august2023.smallworldlabs.com',
'Origin': 'https://august2023.smallworldlabs.com',
'Referer': 'https://august2023.smallworldlabs.com/exhibitors',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'X-Requested-With': 'XMLHttpRequest',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache'
}Two headers are used: the first to access the page (to get session/cookies) and the latter to grab Ajax’s data.
json_data = {
'limit': '50',
'offset': '0',
'module': 'organizations_organization_list',
'site_page_id': '3000',
'method': 'paginationhandler',
'template': 'generic_items',
'mCell': '2_0',
'mId': '0',
'page_id': 'openAjax',
'ajaxType': 'paginate',
'tk': '',
'tm': ''
}When scraping Ajax’s data, you must pass the POST body parameters along with the requests. The body parameters are from the previous step, with some adjustments, i.e., setting the tk and tm empty.
For moving between pages, the script will change the offset parameter. Since the limit is set to 50 (you’ve tried anything greater than 50, but the server gives only 50 data at max), you can use the following formula to get the offset parameter.
| Page | offset | offset = (Page – 1) * limit |
| 1 | 0 | 0 = (1 – 1) * 50 |
| 2 | 50 | 50 = (2 – 1) * 50 |
| 3 | 100 | 100 = (3 – 1) * 50 |
“And how do I know how many pages exist?” says one man in your head.
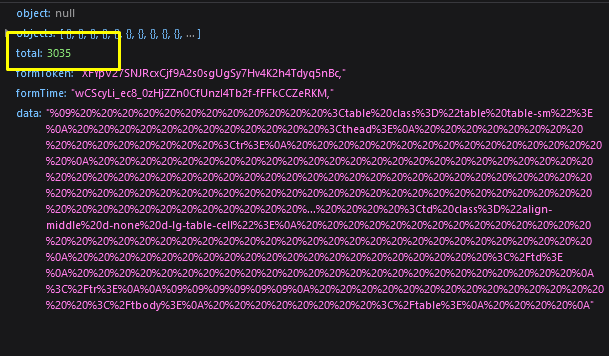
From the Response Tab, you already knew there are 3035 data exists. Divide by the limit, 50, you get 61 pages. But you can always rely on the script to do the calculation; hardcoding the total pages is unnecessary.
with requests.Session() as s:
page_url = 'https://august2023.smallworldlabs.com/exhibitors#exhibitor-list'
r = s.get(page_url, headers=page_headers, verify=False)
limit = 50
json_data['limit'] = str(limit)
pages = 5
current_page = 1
next_page = True
all_data = []
base_url ='https://august2023.smallworldlabs.com'
ajax_url = 'https://august2023.smallworldlabs.com/index.php'
while next_page:
print('Downloading page', current_page, '/', pages)
json_data['offset'] = str((current_page - 1) * limit)
rr = s.post(ajax_url, data=json_data, headers=json_headers, verify=False)
total = int(rr.json()['total'])
pages = math.ceil(total / limit)
table = unquote(rr.json()['data'])
soup = BeautifulSoup(table, 'html.parser')
tds = soup.find_all('a', {'class': 'generic-option-link'})
for td in tds:
if 'exhibitor/' in td.get('href'):
all_data.append({'name': td.text, 'link': base_url + td.get('href')})
current_page += 1
if current_page > pages:
next_page = FalseThis is the heart of the script. The Python requests open the initial page for cookie and session acquisition, iterate every Ajax page, and save the result in a list.
with requests.Session() as s:
page_url = 'https://august2023.smallworldlabs.com/exhibitors#exhibitor-list'
r = s.get(page_url, headers=page_headers, verify=False)Those lines of code indicating the Python requests attempt to open the exhibitor list page.
with requests.Session() as s:
# previous code
limit = 50
json_data['limit'] = str(limit)
pages = 5
current_page = 1
next_page = True
all_data = []
base_url ='https://august2023.smallworldlabs.com'
ajax_url = 'https://august2023.smallworldlabs.com/index.php'You set the limit variable, put placeholder value for pages, and the current_page variable. The all_data variable will hold the data from the scraping process.
with requests.Session() as s:
# previous code
while next_page:
print('Downloading page', current_page, '/', pages)
json_data['offset'] = str((current_page - 1) * limit)
rr = s.post(ajax_url, data=json_data, headers=json_headers, verify=False)
total = int(rr.json()['total'])
pages = math.ceil(total / limit)As long as the next_page variable is set to True, it’ll update to avoid the script running forever; the following codes will be executed.
First, the script will print on the screen which page it processes; this information gives you an idea of whether the script is running. You must also modify the offset key on the json_data dictionary, which will navigate the Ajax page.
After getting a response from the server, the script modifies the total variable to the actual data provided by the server, and the same goes for pages variable.
with requests.Session() as s:
# previous code
while next_page:
# previous code
table = unquote(rr.json()['data'])
soup = BeautifulSoup(table, 'html.parser')
tds = soup.find_all('a', {'class': 'generic-option-link'})The table variable holds the data. You use the unquote function because the original data is decoded, as seen in the Response Tab.
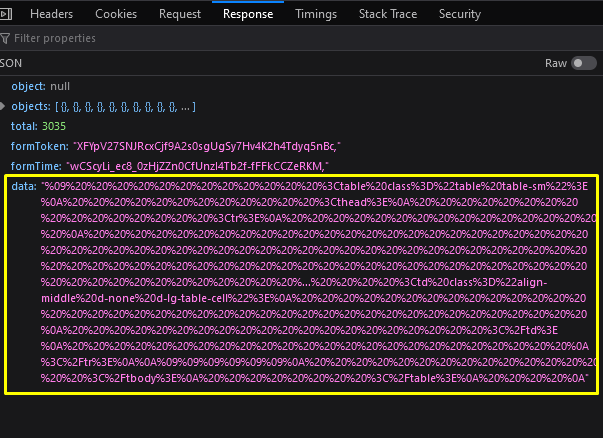
This is another challenge when performing a web scraping, encoded data. Sometimes, the server provides encrypted data; thus, capturing the Ajax data is useless if you don’t know how to decrypt it. Luckily, this time, the server only uses URL encoding for the data, which is easily handled by the unquote function from the Python urllib.parse library.
After decoding the data, you’ll get a table similar to this.
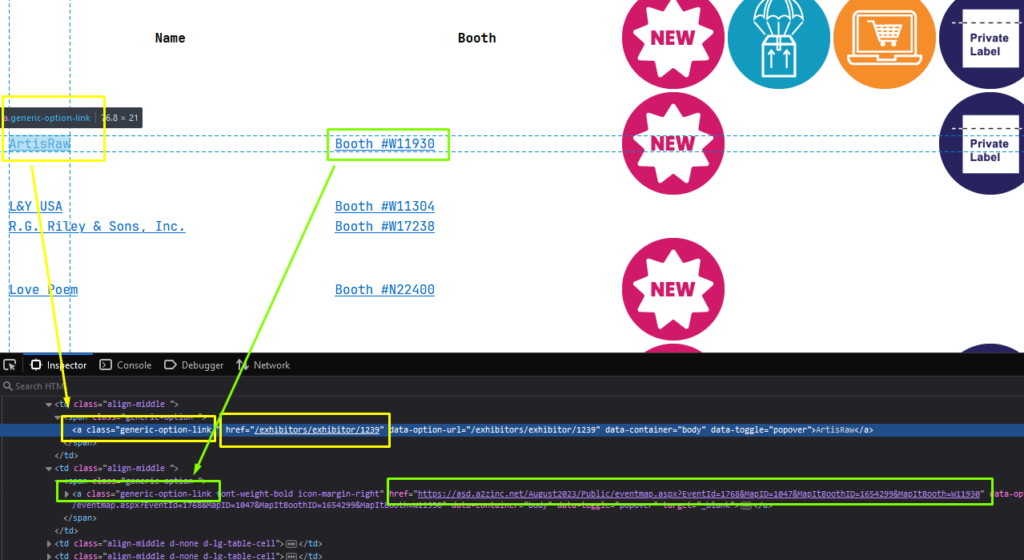
You realize the desired link persists in the anchor tag with a “generic-option-link” class. The href attribute isn’t complete; it only contains the “/exhibitors/exhibitor/number” string, but the Python script will complete it with the base_url variable.
However, there is another anchor tag with the same class name, which you don’t need. You will get rid of it in the following code chunk.
with requests.Session() as s:
# previous code
while next_page:
# previous code
for td in tds:
if 'exhibitor/' in td.get('href'):
all_data.append({'name': td.text, 'link': base_url + td.get('href')})
current_page += 1
if current_page > pages:
next_page = FalseWhile iterating each anchor tag, your Python web scraping Ajax script filters any without “exhibitor/” string on the href attribute. The all_data variable holds the data you wanted.
The next code chunk is used to increase the page to scrape. And put a stop when the last page reached.
with requests.Session() as s:
# previous code
df = pd.DataFrame(all_data)
df.to_excel('smallworld.xlsx', index=False)After scraping all the pages and storing them in the all_data variable, the script converts it to the Pandas Dataframe and exports it as an MS Excel file named smallworld.xlsx. You are using Pandas as you found it provides the easiest way for data manipulation and conversion between different data formats.
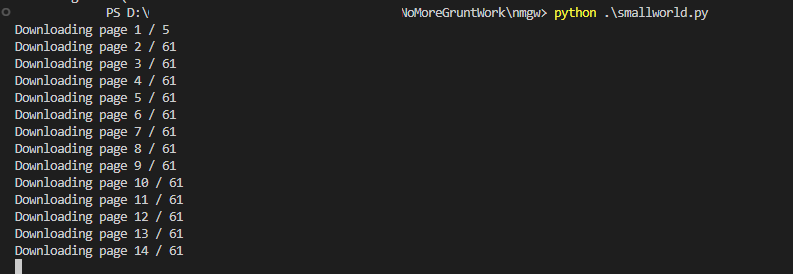
Naming and saving the script to whatever and wherever you want, and run it.
Web Scraping Using Python urllib.request
The first phase gives you 3035 links. Some people may find it plenty, while others find it’s a number that falls short. From your experience, better safe than sorry; you’ll open and save each page and process it later in the third phase.
For the task, you’ll use urllib.request from the Python Standard Library. Using a built-in library makes sure the Python script will always run in multiple environments.
Below is the script. It’s relatively small, 18 lines in total, but it does the job well. The complete script is here.
import os
import pandas as pd
import urllib.request
directory_name = 'smallworld'
if not os.path.exists(directory_name):
os.mkdir(directory_name)
df = pd.read_excel('smallworld.xlsx')
df.sort_values(by=['link'], inplace=True)This part contains libraries used and creating a directory, named smallworld, to store all downloaded HTML. The df variable is a Pandas DataFrame, which contains all links needed to download.
i = 0
for index, row in df.iterrows():
filename = os.path.join(directory_name, row['link'].split('/')[-1] + '.html')
urllib.request.urlretrieve(row['link'], filename)
print(i, row['link'])
i += 1Then, the script iterates over DataFrame, creating filenames from the individual exhibitor’s page and the urlretrieve function used to download the page.
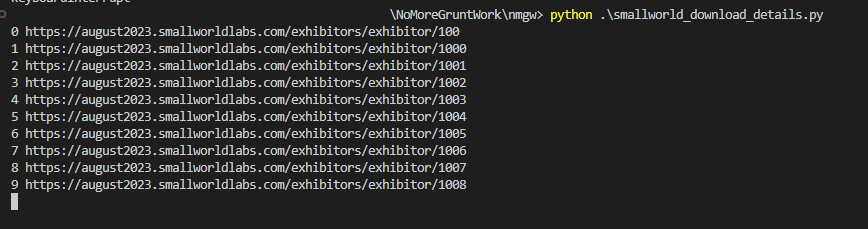
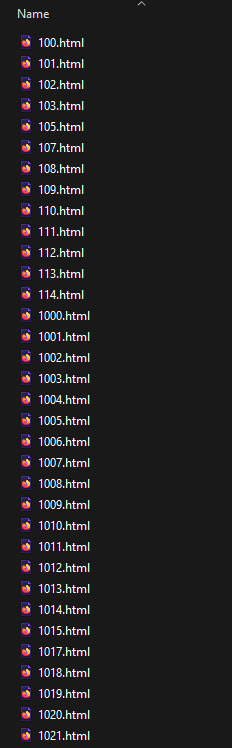
Here is the Python urllib.request when you catch it in the wild. And images below show the contents of smallworld directory.
Using Python BeautifulSoup to parse HTML
While waiting for the Python urllib.request to scrape all pages, you can write a Python script to parse downloaded HTML files in the smallworld directory.
After inspecting the element, you know all your target data lies in the div tag with the “row small no-gutters mb-3” class. Each div contains two children, one child (div) with the “col-4” class, and the other uses the “col-8” class.
The “col-4” div has a child that contains the data name (What We Do, Website, Address, etc.) and the “col-8” div contains the data itself.
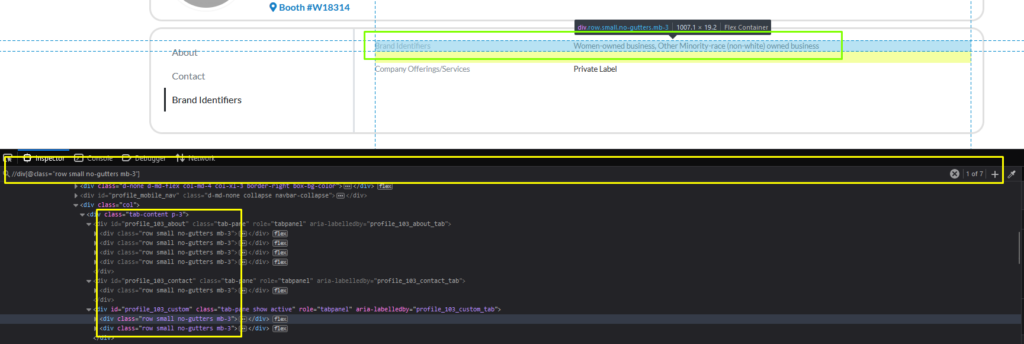
Right-click the element and select Inspect to open the Inspector Tab on Developer Tools.
Let’s write the last Python script to parse the HTML file using the BeautifulSoup library. Again, the complete code can be found here.
import os, glob
import pandas as pd
from bs4 import BeautifulSoup
directory_name = 'smallworld'
all_files = glob.glob(os.path.join(directory_name, '*.html'))
all_data = []
i = 0This part loads all libraries, reads all HTML filenames in the smallworld directory, and initializes the all_data variable to hold data.
# previous code
for filename in all_files:
with open(filename, 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html, 'html.parser')
rows = soup.find_all('div', {'class': 'row small no-gutters mb-3'})
temp_data = {}
for row in rows:
data_name = row.find('div', {'class': 'col-4'}).find('div').text.strip()
data_value = row.find('div', {'class': 'col-8'}).find('div').text.strip()
temp_data[data_name] = data_value
all_data.append(temp_data)
print(i, filename)
i += 1With all files, open it, parse using Beautiful Soup, and pick the elements to store in the all_data variable.
# previous code
for filename in all_files:
# previous code
df = pd.DataFrame(all_data)
df.to_excel('smallworld_details.xlsx', index=False)The last part is converting the all_data list into Pandas DataFrame and exporting it to MS Excel.
Run it.
And voila!
If everything goes well, you’ll get a similar Excel file.

Tl;dr
Full Python requests script to scrape Ajax contains Exhibitor List
import requests, math
import pandas as pd
from bs4 import BeautifulSoup
from urllib.parse import unquote
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
page_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.5',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:102.0) Gecko/20100101 Firefox/102.0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1'
}
json_headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.5',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'august2023.smallworldlabs.com',
'Origin': 'https://august2023.smallworldlabs.com',
'Referer': 'https://august2023.smallworldlabs.com/exhibitors',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'X-Requested-With': 'XMLHttpRequest',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache'
}
json_data = {
'limit': '50',
'offset': '0',
'module': 'organizations_organization_list',
'site_page_id': '3000',
'method': 'paginationhandler',
'template': 'generic_items',
'mCell': '2_0',
'mId': '0',
'page_id': 'openAjax',
'ajaxType': 'paginate',
'tk': '',
'tm': ''
}
with requests.Session() as s:
page_url = 'https://august2023.smallworldlabs.com/exhibitors#exhibitor-list'
r = s.get(page_url, headers=page_headers, verify=False)
limit = 50
json_data['limit'] = str(limit)
pages = 5
current_page = 1
next_page = True
all_data = []
base_url ='https://august2023.smallworldlabs.com'
ajax_url = 'https://august2023.smallworldlabs.com/index.php'
while next_page:
print('Downloading page', current_page, '/', pages)
json_data['offset'] = str((current_page - 1) * limit)
rr = s.post(ajax_url, data=json_data, headers=json_headers, verify=False)
total = int(rr.json()['total'])
pages = math.ceil(total / limit)
table = unquote(rr.json()['data'])
soup = BeautifulSoup(table, 'html.parser')
tds = soup.find_all('a', {'class': 'generic-option-link'})
for td in tds:
if 'exhibitor/' in td.get('href'):
all_data.append({'name': td.text, 'link': base_url + td.get('href')})
current_page += 1
if current_page > pages:
next_page = False
df = pd.DataFrame(all_data)
df.to_excel('smallworld.xlsx', index=False)Full Python urllib.request script to download all pages
import os
import pandas as pd
import urllib.request
directory_name = 'smallworld'
if not os.path.exists(directory_name):
os.mkdir(directory_name)
df = pd.read_excel('smallworld.xlsx')
df.sort_values(by=['link'], inplace=True)
i = 0
for index, row in df.iterrows():
filename = os.path.join(directory_name, row['link'].split('/')[-1] + '.html')
urllib.request.urlretrieve(row['link'], filename)
print(i, row['link'])
i += 1Full Python BeautifulSoup script to parse HTML local files
import os, glob
import pandas as pd
from bs4 import BeautifulSoup
directory_name = 'smallworld'
all_files = glob.glob(os.path.join(directory_name, '*.html'))
all_data = []
i = 0
for filename in all_files:
with open(filename, 'r', encoding='utf-8') as f:
html = f.read()
soup = BeautifulSoup(html, 'html.parser')
rows = soup.find_all('div', {'class': 'row small no-gutters mb-3'})
temp_data = {}
for row in rows:
data_name = row.find('div', {'class': 'col-4'}).find('div').text.strip()
data_value = row.find('div', {'class': 'col-8'}).find('div').text.strip()
temp_data[data_name] = data_value
all_data.append(temp_data)
print(i, filename)
i += 1
df = pd.DataFrame(all_data)
df.to_excel('smallworld_details.xlsx', index=False)Final Note
As you returned to Mr. Jenning’s office with the completed exhibitor list, you couldn’t help but smile at the amusing adventure. With a playful twinkle in his eye, the funny boss congratulated you on your successful mission.
“Jhon,” he said, “remember this: work should be productive but enjoyable!”
You appreciate his advice and challenge. But suddenly, your stomach starts screaming, a dizzying sensation washed over, and your vision blurs.
Do you have the same experience? Comment below.
Cover Photo by Scott Umstattd on Unsplash

Is there free software or online database to keep track of scheduled blog posts? I would also like it to keep a record of past and future posts. I am trying to avoid creating a spreadsheet in Excel..
Hi Olen, mind elaborating more? Do you have blog posts that need to be automated?