
Your employer ran an office building and decided to implement a new alarm system he heard from his friend. He then gave you a task to get in touch with every electrician in the town and ask for a quote for the new system. So you decided to send an email to every electrician. Your email template is ready but needs to be sent, and you don’t yet have the email addresses. You know some sites provide the electrician’s email addresses. You just need to pull the data.
Tl;dr
Code
import requests
import json
import re
import pandas as pd
from bs4 import BeautifulSoup
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.5',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'www.yellowpages.com.au',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:102.0) Gecko/20100101 Firefox/102.0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1'
}
all_data = []
with requests.Session() as s:
for i in range(1, 30):
url_to = 'https://www.yellowpages.com.au/find/electricians-electrical-contractors/nsw/page-' + str(i)
print(url_to)
r = s.get(url_to, verify=False, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
scripts = soup.find_all(lambda tag: tag.name == 'script' and not tag.attrs)
initial_state = {}
for script in scripts:
if 'INITIAL_STATE' in script.contents[0]:
ss = script.contents[0].strip()
txt = re.search(r'= {(.*)};', ss).group(1)
initial_state = json.loads('{' + txt + '}')
data = initial_state['model']['inAreaResultViews']
all_data.append(data)
data_csv = []
for data in all_data:
for row in data:
data_csv.append({
'name': row['name'],
'email': row['primaryEmail'],
'website': row['website'],
'legal_id': row['legalId'],
'description': row['longDescriptor']
})
df = pd.DataFrame(data_csv)
df.to_csv('yellowpages.csv', index=False, sep='\t')
Target
https://www.yellowpages.com.au
Output
A CSV with columns like below.
- name
- website
- legal_id
- description
Tool(s)
- Python Requests
Pro(s)
- Raw data lie in JavaScript
- Pagination through URL is easy to manage
Cons
- Need to use IP from a certain region (Australia or NZ)
- Can’t move after the 29th page of the results
The Situation
If you are old enough, you’ll remember how we found our plumber by skimming the telephone directory. We searched on a yellow paper, got the number then dialed the number. That was the situation when we had no internet back then.
Your boss might only ask to call some contractors in the olden setting because that was plenty enough things to do. But in the internet era, your boss’s goal grows when the data is more accessible for acquisition. He wants more. In the modern era, he needed to reach out to every electrician in the town to ensure he’d get the most beneficial quote.
Luckily there are websites providing electricians’ data. What you need next is a method to pull the data.
yellowpages.com.au
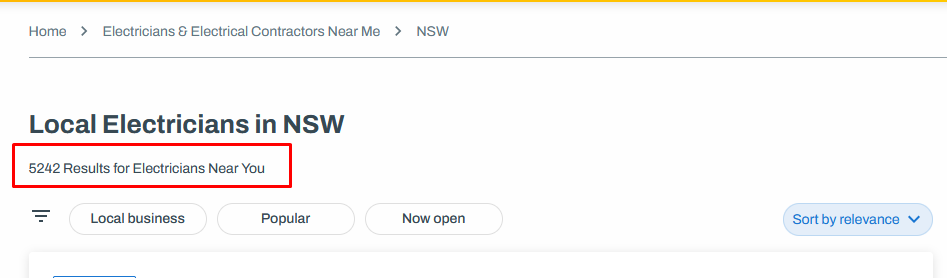
For the Australian folks, there is yellowpages.com.au provides a business list completed with phone number, email, address, and other relevant information. For example, from the image below, we know there are 5,240 electricians in NSW. Enough to complete the boss task.

Sure we want to grab all the data. That’s why we need to automate the process and let the computer do the donkey work.
For the sake of simplicity, here is our initial target URL. We’ll grab each result from this URL.
https://www.yellowpages.com.au/find/electricians-electrical-contractors/nsw
The Manual Labor
Every automated process has its own manual work. In our case, we need to identify how to access the desired data and create a script to replace the humans required.
Open Page
Opening the page is one small step for man, one giant leap for mankind.
But.
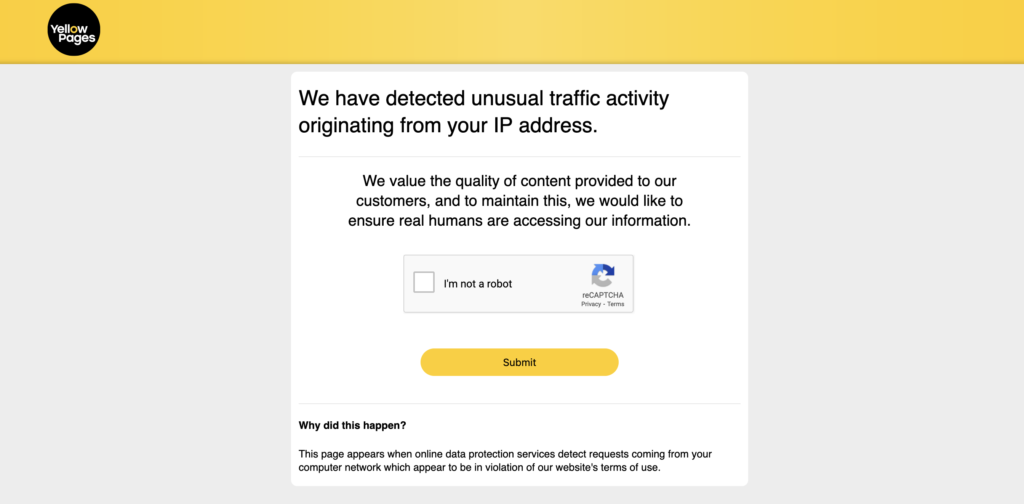
The server says, “thou shall not pass.”
Sometimes we face this kind of “welcoming page” because, you know, every folk sees scraping activity differently.
Some servers curtail requests from some regions.
Suppose you are not in the area as wanted by the server. In that case, we can use some methods: 1) VPN, set up the location to please the server, 2) employ a cloud machine in the area, and 3) use a proxy.
Where are the “raw materials?”
After managing the “welcoming page” situation, we are ready to scrape our first page.
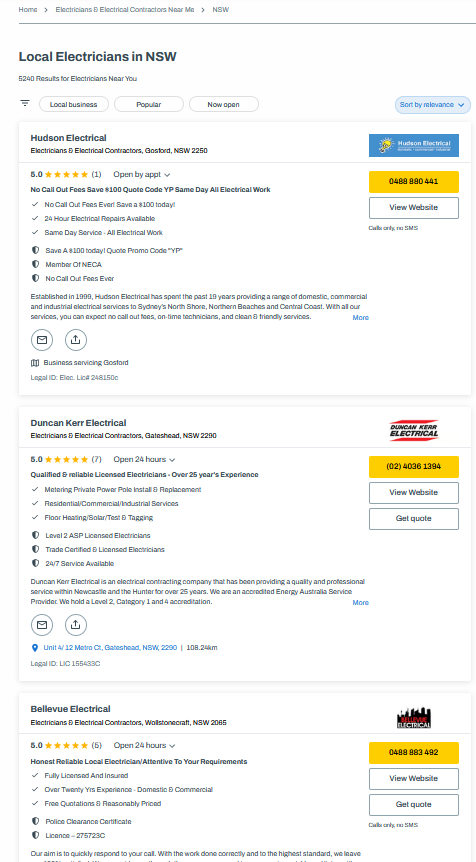
Nowadays, websites are heavily JavaScript-powered. The server provides raw data, usually in JSON format. On the client side, using JavaScript, the browser presents it in the desired format.
Yellow Pages choose a slightly different approach. The raw data is embedded in the page’s source as a JavaScript variable on the yellow page’s site. It then uses the JS function to display the formatted data on the page.
We can search for the unique term we targeted on the page source to identify the variable containing our desired data. For example, we can search for the contractor’s name. If there are multiple results, we can pick the most complete ones.
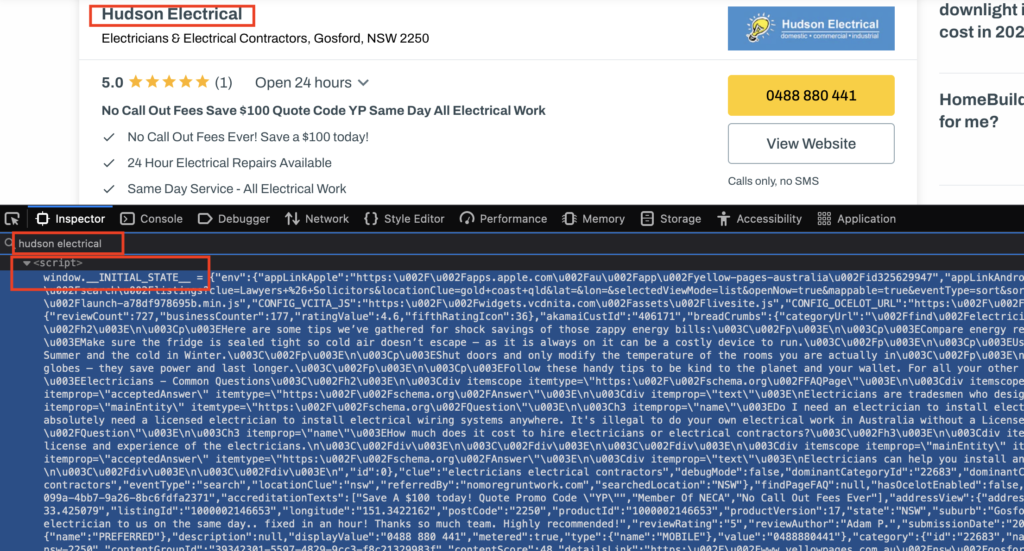
If we remove the JavaScript variable name (window.__INITIAL_STATE__ =) and the semicolon (;) at the end, we’ll get a clean JSON containing raw data for the Yellow Pages. Primarily we may need to review the model -> inAreaResultViews part.
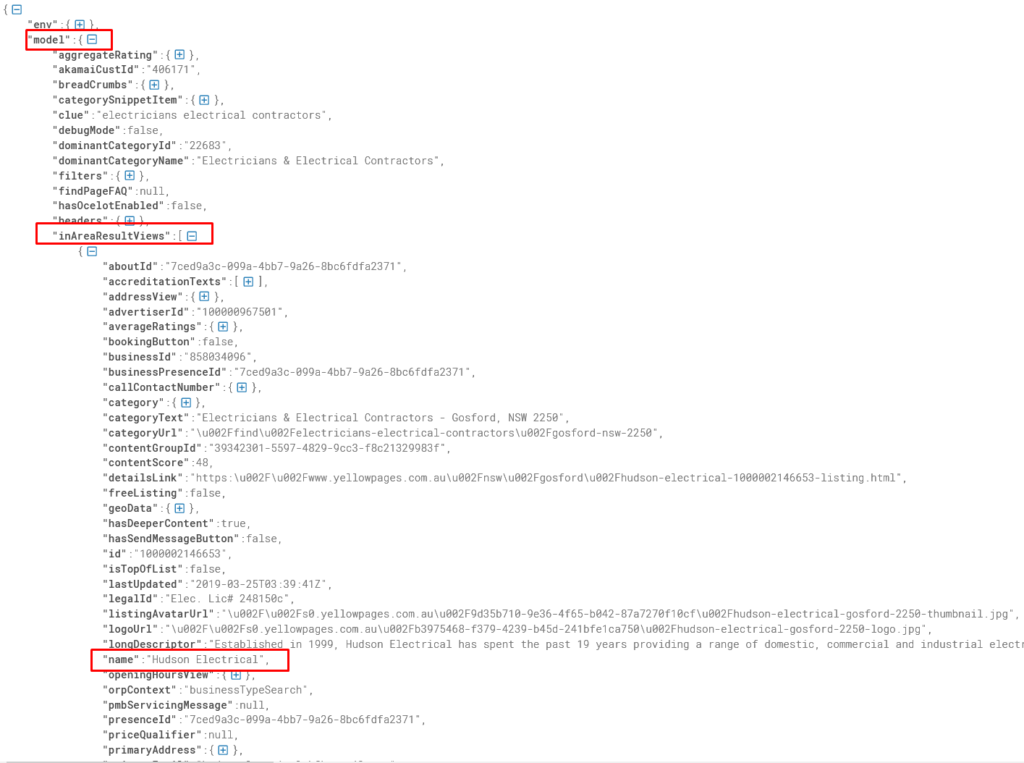
We can check our findings by mapping them to the actual displayed information.
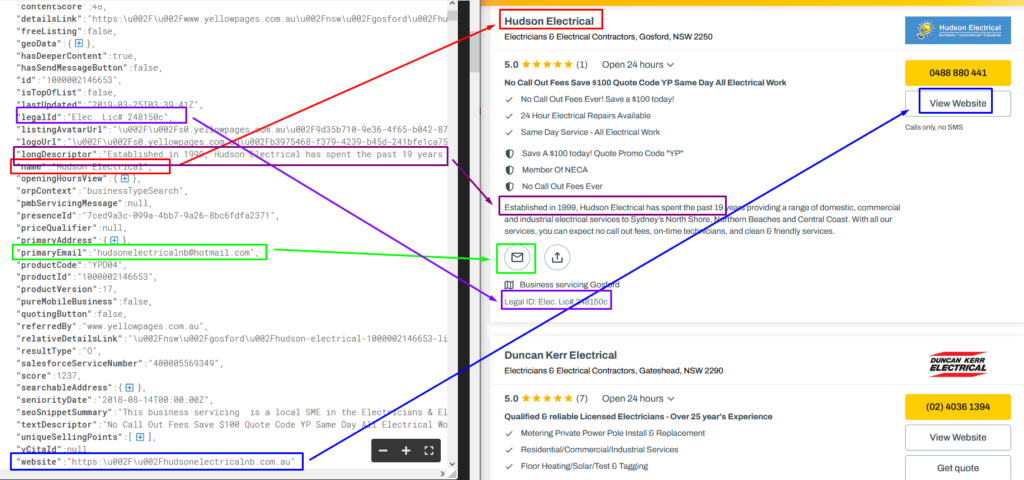
The contractor’s name, the description, Legal ID, website URL (hidden unless we click the button), and the email on the JavaScript is the same as displayed on the page.
Cool. Looks like we figured out which JavaScript chunk handled the correct data.
It’s a script tag containing window.__INITIAL_STATE__ at the beginning.
Get All Data
There are 5,242 results we want to scrape.
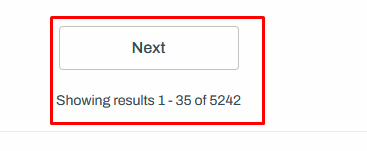
Scrolling down, we’ll see the Next button and the information about where we are now regarding results navigation. We can navigate to the following page by clicking the Next button.
Navigating to the second page, change the URL from:
https://www.yellowpages.com.au/find/electricians-electrical-contractors/nsw
To:
https://www.yellowpages.com.au/find/electricians-electrical-contractors/nsw/page-2
There is a page-2 key added to the URL. It makes our scraping process easier because the pagination is embedded in the URL in a human-readable format.
Each page contains 35 results. If we do the quick math, there should be 150 pages total (5,242/35 = 149.77). But.
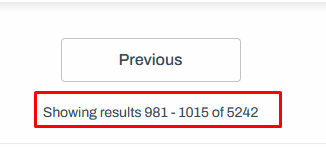
The server stopped providing the Next button after page 29th, with the total results being 1,015. What a shame.
Solution: We may apply more filters to encounter this, so the results are below the 1,000 mark.
For now, we’ll scrape only the first 29 pages.
The script
One Page
Below is the code used to grab one-page data.
import requests
import json
import re
import pandas as pd
from bs4 import BeautifulSoup
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.5',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'www.yellowpages.com.au',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:102.0) Gecko/20100101 Firefox/102.0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1'
}
url_to = 'https://www.yellowpages.com.au/find/electricians-electrical-contractors/nsw'
with requests.Session() as s:
r = s.get(url_to, verify=False, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
scripts = soup.find_all(lambda tag: tag.name == 'script' and not tag.attrs)
initial_state = {}
for script in scripts:
if 'INITIAL_STATE' in script.contents[0]:
ss = script.contents[0].strip()
txt = re.search(r'= {(.*)};', ss).group(1)
initial_state = json.loads('{' + txt + '}')
The initial_state variable holds our data.
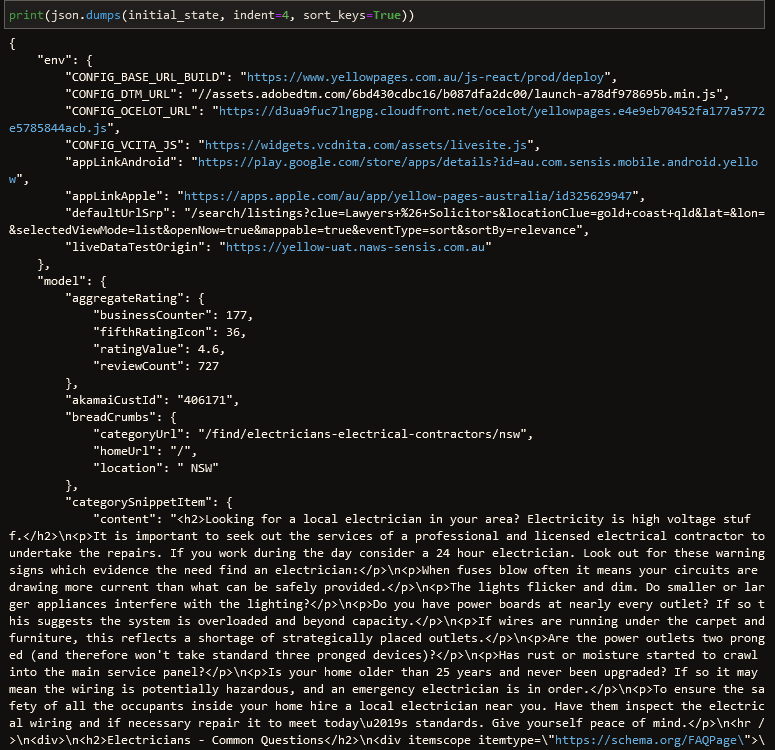
Before moving forward, let’s break down the existing code.
import requests import json import re import pandas as pd from bs4 import BeautifulSoup from requests.packages.urllib3.exceptions import InsecureRequestWarning requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
These are libraries used for the project in which requests is the main character. The two last lines are used for the sake of our convenience by hiding the InsecureRequestWarning message.
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.5',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'www.yellowpages.com.au',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:102.0) Gecko/20100101 Firefox/102.0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1'
}
Our requests to the server should use headers. Otherwise, the requests will be rejected.
We can gather which headers are needed from the Network tab on browsers’ Web Developer Tools.
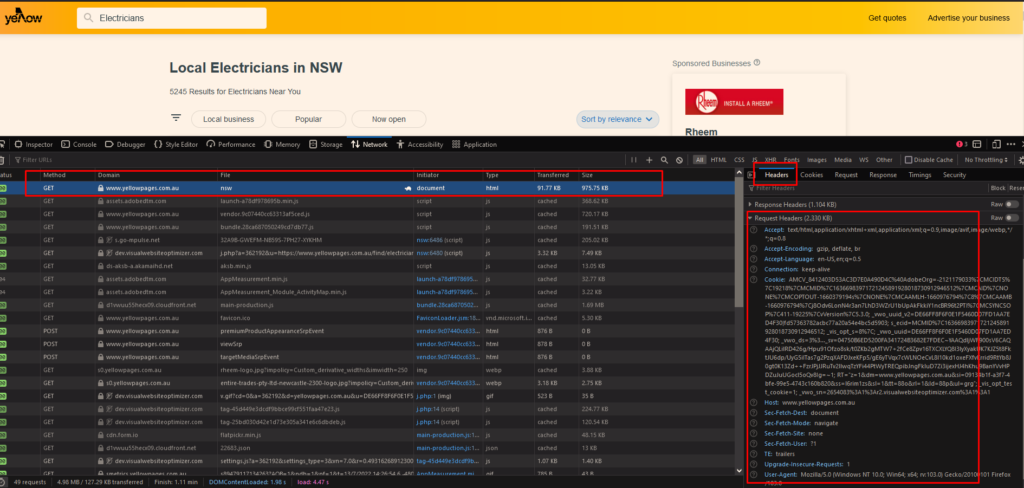
url_to = 'https://www.yellowpages.com.au/find/electricians-electrical-contractors/nsw'
with requests.Session() as s:
r = s.get(url_to, verify=False, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
scripts = soup.find_all(lambda tag: tag.name == 'script' and not tag.attrs)
initial_state = {}
for script in scripts:
if 'INITIAL_STATE' in script.contents[0]:
ss = script.contents[0].strip()
txt = re.search(r'= {(.*)};', ss).group(1)
initial_state = json.loads('{' + txt + '}')
We know the data reside on a script tag from the previous step. Apparently, there are multiple script tags on the page. So we need to identify which tag is our target.
Clues are 1) the script tag doesn’t have an attribute, and 2) it contains the INITIAL_STATE string. Below code chunk applies the clues.
scripts = soup.find_all(lambda tag: tag.name == 'script' and not tag.attrs)
initial_state = {}
for script in scripts:
if 'INITIAL_STATE' in script.contents[0]:
ss = script.contents[0].strip()
The rest of the code is for cleaning the data, using Regex, and creating a JSON variable named initial_state.
txt = re.search(r'= {(.*)};', ss).group(1)
initial_state = json.loads('{' + txt + '}')
The initial_state variable contains any other data we wouldn’t care about. We just want the model -> inAreaResultViews part.
data = initial_state['model']['inAreaResultViews']
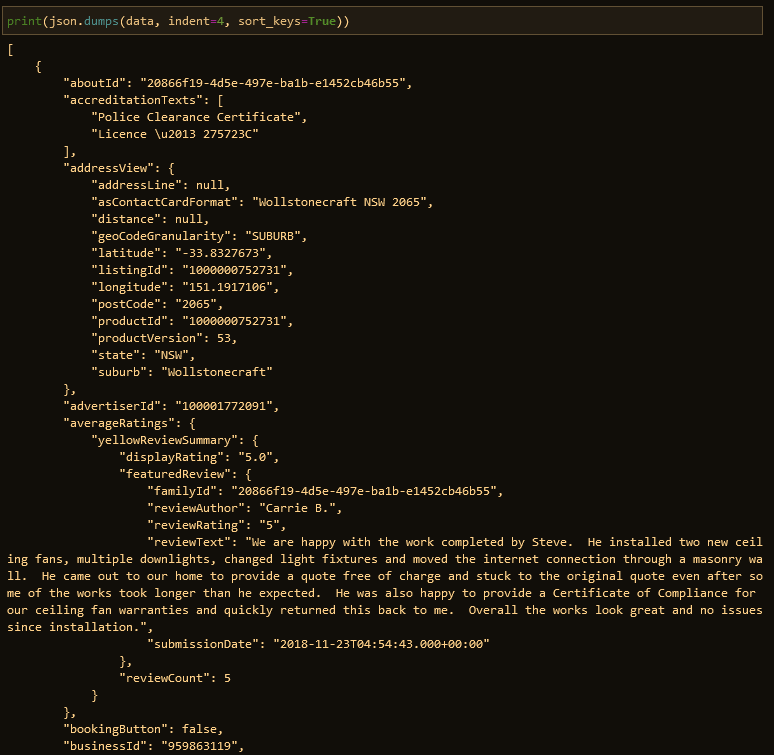
To this moment, we can dump the data as a JSON file, i.e., with the below code.
with open('page1.json', 'w') as ofile:
ofile.write(json.dumps(data, indent=4))
All Pages
But our ultimate goal is to pull all data, at least for 29 pages we do have access to. Modifying the previous code to accommodate scraping 29 pages makes us have the below code (new part commented).
import requests
import json
import re
import pandas as pd
from bs4 import BeautifulSoup
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.5',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'www.yellowpages.com.au',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:102.0) Gecko/20100101 Firefox/102.0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1'
}
with requests.Session() as s:
all_data = [] # new part
for i in range(1, 30): # new part
url_to = 'https://www.yellowpages.com.au/find/electricians-electrical-contractors/nsw/page-' + str(i) # new part
print(url_to) # new part
r = s.get(url_to, verify=False, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
scripts = soup.find_all(lambda tag: tag.name == 'script' and not tag.attrs)
initial_state = {}
for script in scripts:
if 'INITIAL_STATE' in script.contents[0]:
ss = script.contents[0].strip()
txt = re.search(r'= {(.*)};', ss).group(1)
initial_state = json.loads('{' + txt + '}')
data = initial_state['model']['inAreaResultViews']
all_data.append(data) # new part
Surprisingly the process of scraping 29 pages was error-free. The server didn’t cut the cord after several pages were scraped.
The all_data variable holds data from 29 pages. We will convert the JSON data to a csv format using the below code.
data_csv = []
for data in all_data:
for row in data:
data_csv.append({
'name': row['name'],
'email': row['primaryEmail'],
'website': row['website'],
'legal_id': row['legalId'],
'description': row['longDescriptor']
})
df = pd.DataFrame(data_csv)
df.to_csv('yellowpages.csv', index=False, sep='\t')

Awesome, we got 1,015 emails with ease.
Final Note
Today our workload couldn’t handle with our bare hands. Employing a computer to do the grunt task is a must. The only challenge is, do we know which technology best fits our situation?
Cover Photo by Soroush Karimi on Unsplash
